Music Processing Suite features an evolutionary algorithm capable of generating musical compositions according to statistical specifications. The basic structure of the algorithm is depicted below:
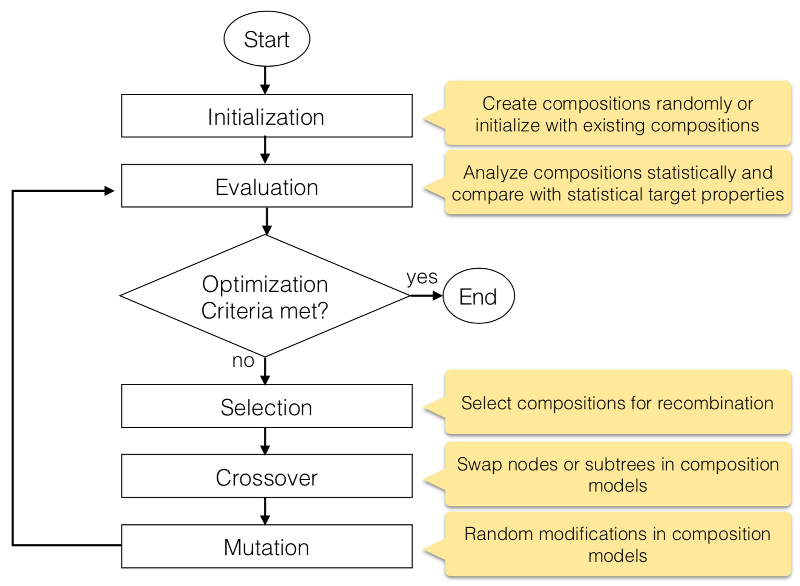
The algorithm takes statistical criteria of various musical aspects as input and produces a composition model complying as much as possible to the given statistics. The basic idea is illustrated here:
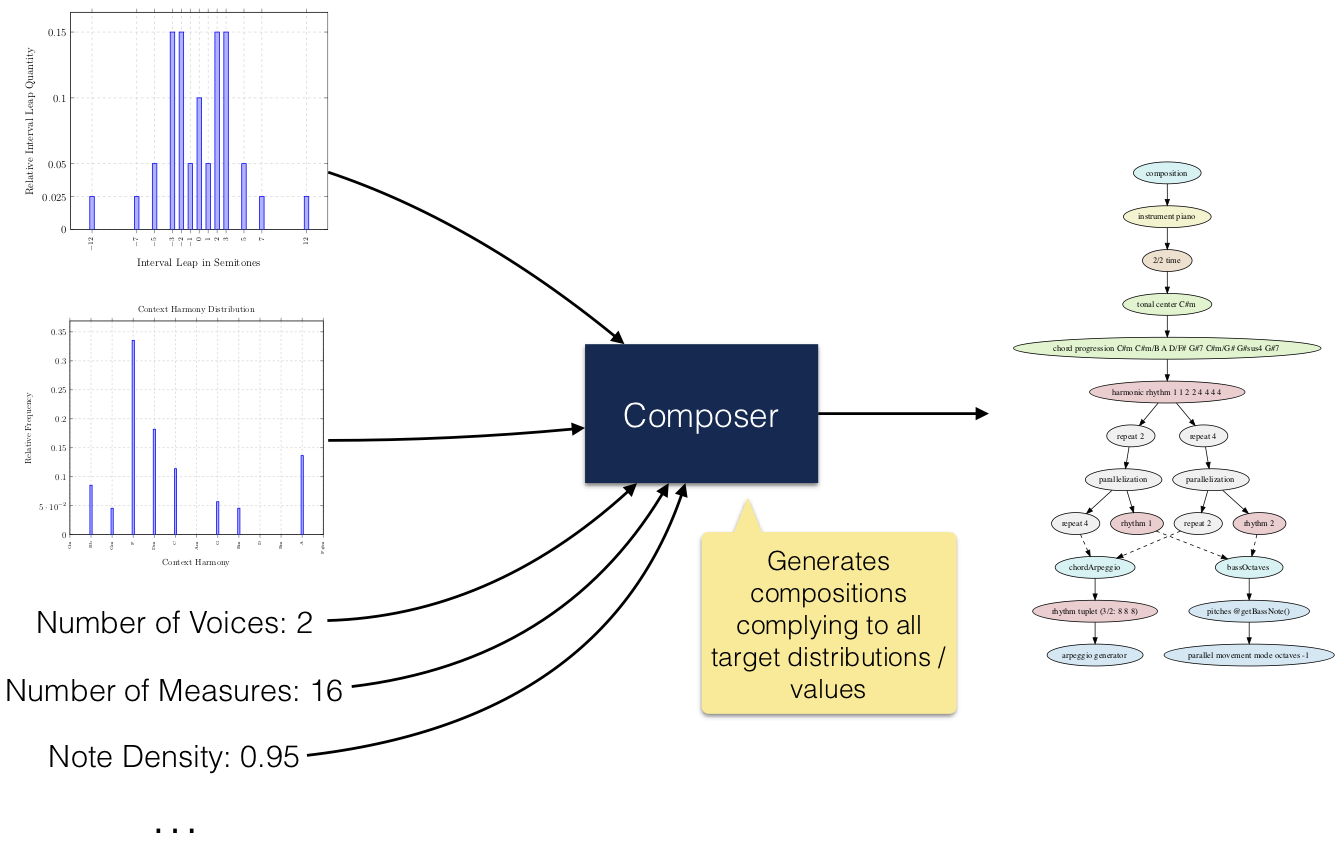
The following musical and structural aspects can be optimized by the algorithm:
- Absolute Duration of the Piece
- Number of Measures
- Number of Voices
- Number of Notes
- Note Density
- Note Duration Distribution
- Rest Duration Distribution
- Beat Distribution (Point of Time within Measures)
- Time Signature Distribution
- Instrumentation Distribution
- Pitch Range
- Horizontal Interval Leap Distribution
- Vertical (Simultaneously Audible) Note Distribution
- Vertical (Simultaneously Audible) Interval Distribution
- Harmonic Progression Length
- Harmonic Progression Circle of Fifths Distance Distribution (Harmonies)
- Harmonic Progression Circle of Fifths Distance Distribution (Keys)
- Harmony Compliance (Overall)
- Harmony Compliance (Bass Notes)
- Harmony Compliance (Root Notes)
- Scale Compliance (relative to Key)
- Scale Compliance (relative to Harmony)
- Global Dissonance Average
- Global Dissonance Standard Deviation
- Model Tree Depth
Depending on the selection and configuration of the listed aspects, various applications of the algorithm are possible, which are described below.
Style Imitations
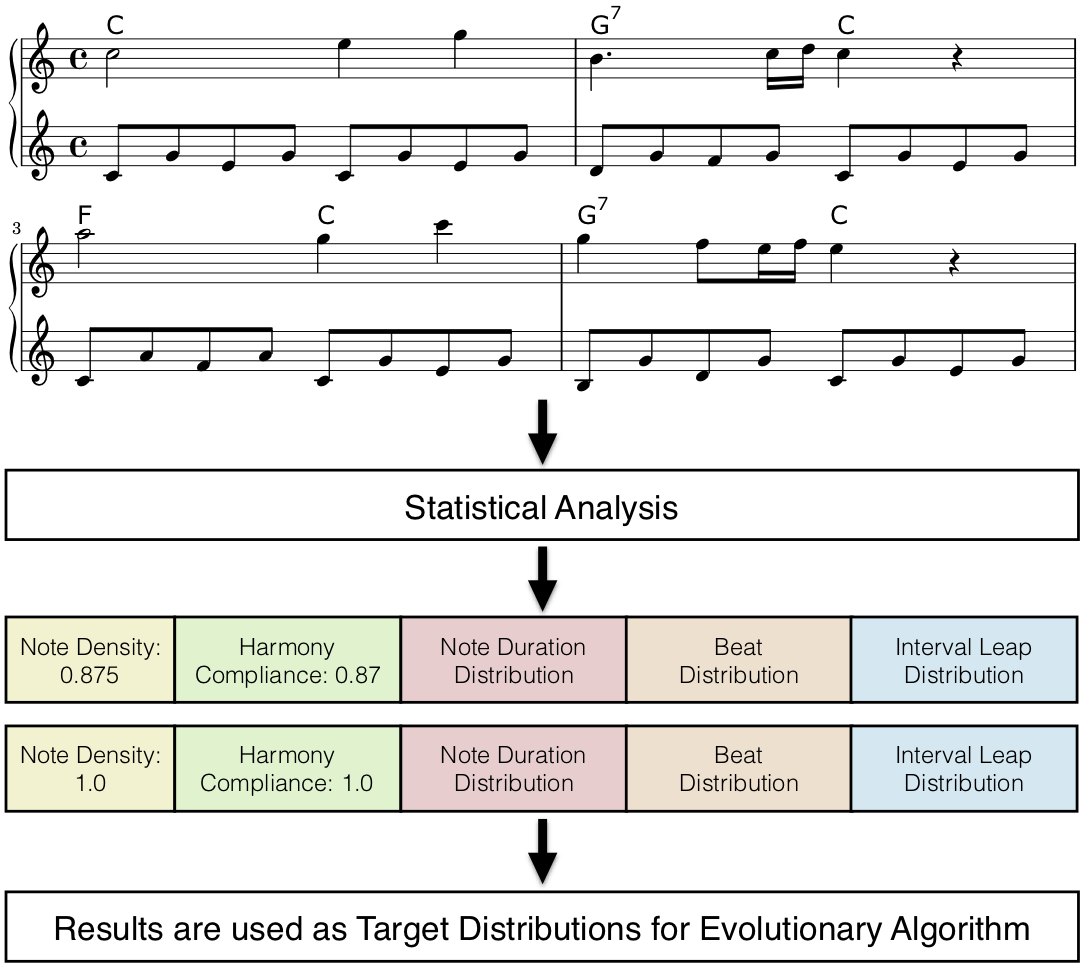
When supplying statistical analysis results of existing pieces, the generated compositions will result in style imitations. Mozart’s Piano Sonata No. 16 in C major, K. 545 is used for the following example. The methodology is presented in the following figure:
 Listen to the original:
Listen to the original:
As shown in the the illustration above, the following statistical features were selected to create the style imitation for each voice separately:
- Note Density
- Harmony Compliance (Overall)
- Note Duration Distribution
- Beat Distribution
- Interval Leap Distribution
This is one of the resulting style imitations:

And it sounds like this:
The more statistical features are used, the closer the style imitation will resemble the original composition.
Improvisations
If just a small set of features is given as target, the algorithm will have more musical “freedom” during the composition process, which results in improvisation-like pieces like this blues:

Multiple Musical Sections and Randomly Generated Statistical Distributions
The algorithms is also capable of generating pieces with changing statistical properties during the course of the piece. This is required to emulate musical changes or developments, which are vital in music. The following example demonstrates a piece with two logical sections which have different musical properties in each section and voice. The statistical target features were generated randomly. This means that this piece was generated without any prior statistical knowledge of human compositions. (This example also indicates that the computer still needs some coaching regarding harmony notation *g*)

IDE Integration
A graphical user interface to experiment with the algorithm is available since MPS version 1.5.0.